これからのコンピューターを夢想してみる - EEIC Advent Calendar Day 13
この記事はeeic Advent Calendar 2015の13日目の記事になります。
はじめに
僕はτ研で次世代不揮発性メモリ向けのLinuxのファイルシステムを作っています。このテーマは僕がM1のときに、「5年〜10年後のコンピューターシステムについてて考えてみよう」と思っていろいろ調べてみたのをきっかけにして思いついた内容になります。せっかくそのときにいろいろ調べたので、知識のupdateも兼ねて僕の考えるこれからのコンピューターについて適当にまとめつつ、eeic Advent Calendarなので最後にウチの研究室おいでよという宣伝もしとこうかな。
ただ、あくまでもこれは一人の修士学生が考えた(しかもゆるふわブログ向けの)内容ですので、大いに間違いや思い込みが含まれている可能性があります。指摘やご意見等気軽にしていただけると喜びます。 (引用はできるだけしたいですが、調べてると時間がかかるので嘘を覚悟で僕が覚えていること、考えていることをひとまずごっちゃでかいちゃいます。)
もくじ
ネットワーク…も重要な要素だけど、全く知らないのでこれは割愛。
いろいろなコンピューターとCPUのトレンド
最近では、CPUといってもいろいろなタイプのものがあります。ノーパやデスクトップといったいわゆる「パソコン」に搭載されているような, Core iシリーズやAtomなんかもそうですし、Xeonのような高性能サーバー向けや、ARMに代表されるようなモバイル向けなんかは有名なところだとおもいます。さらに、Intelが出しているEdisonやCurieといったIoT向けの超低消費電力な、SoC (System on Chip) と呼ばれる種類のものもあります。
このように多彩な"CPU"が出てきている背景には、開発のトレンドの推移があると考えられます。 ここ数年は、1コアの性能が頭打ちになってきていて、たくさんのコア(~16物理コア程度)のCPUが手軽に、秋葉原なんかで買えるようになっている、というのは有名な話かと思います。この理由は、 「デナードスケーリング」が完全には成り立たなくなっているということがあります。これは簡単に言うと、1/kのプロセスでつくれば電圧は1/kになり、遅延は1/kになり、消費電力/デバイスは1/k2になるので、同じ大きさのプロセッサにたくさんトランジスタを載せても電力は変わらず性能が上がるという素晴らしい法則です。ただ、現在では、スイッチング速度をあげるのに重要だった低電圧化も電圧がスレッショルド電圧に近づき、単純に1/kにはできなくなった、という現状があるようです。(ちなみに、こういう内容は大学院のアドバンスド・コンピューターアーキテクチャで軽く勉強したりします。) そこで、クロックを上げるのではなく、トランジスタ数で勝負!となったけど、たくさんトランジスタつかって複雑なこと(スーパースカラ、アウトオブオーダー、賢いキャッシュ、SIMD命令によるベクトル演算など)をやってもあんまりいい感じにならないな、ということで出てきたのがマルチコアです。 (ちなみに、簡単なプログラムではどれくらい”いい感じ”にならないかというのを最後にAppendixとして載せておきます。)
しかし、プロセスを微細化してたくさんたくさんトランジスタを載せ、ぎちぎちに積むと、スケーリングが成り立たない今では消費電力が増えていってしまいます。特に問題になるのがリーク電流とよばれるもので、これは微細化したトランジスタのOFF時に流れちゃう電流、ということでいいのかな?(このへんは詳しくない)なので、すべてのトランジスタを常時利用して、フルパワーで全部動かす、というのは電力供給という点で難しいようで、同時には使えない領域が生まれていまいます。これが「ダークシリコン」と呼ばれる問題です[参考:モバイルSoCにおけるダークシリコンの呪縛]。今は電力供給が問題、と言っていますが、それが問題無くなったとしても、発熱の面で問題なのではないでしょうか。
エンジニアリング的な回避策として、ターボブーストと呼ばれる、1コアだけを高クロックで動かす技術はこのために生まれたもののようです。 ほかにも、QSVというIntelのCPUにくっついてる動画エンコード用のハードウェアなんかも、余ったトランジスタの利用先として都合よかったのかな、なんて個人的に思ったりしています。このように、余ったトランジスタの利用先を、特定用途の回路に用いるというのが現在のダークシリコンの利用策のようです。この「特定用途の回路」の究極系(たぶん)として、FPGAを統合しようという動きもあるようです。Intelが2大FPGAメーカーのうちのひとつ、Alteraを買収したのは記憶にあたらしいことだと思います。[参考:なぜインテルはアルテラを買収し、FPGAをXeonに統合しようとしているのか?] FPGAは最近どうやらアプリケーションレベルでも興味を持たれているようで、特にHFT (High Frequency Trading) の分野では意欲的に取り組まれているようです。[参考:文字通り「ネットワークがコンピューター」な金融HFTでのFPGAの使われ方] IntelのXeon FPGAに関してはこの記事がとてもよくまとめてくれています。[参考:インテル、ISCA 2015でXeon+FPGAの詳細を公開] コンピュータアーキテクチャ系のトップカンファレンスであるISCAで今年IntelがFPGAについて公演してくれていたみたいですね。今後OpenCLでFPGAを高位合成、さらにそれをverilogかなんかでチューニングできるエンジニアが重宝されていくのかもしれません。勉強しなきゃな。
さて、今こんな現状なので、高速化ではなく、低消費電力の方向に舵をきってすすめているというトレンドもあります。これは最近のCoreシリーズの紹介の仕方や、特にあたらしくモバイル向けにできたCore Mシリーズや、Atomシリーズの力のいれようからもわかりますね。もともとモバイル、タブレットではARMが強かったので、今後はIntelとARMのせめぎあいが起こるようです。このあたりは、ある程度の性能をできるだけ低消費電力で実現するという分野なので、ダークシリコン問題を回避する策のひとつともいえるかもしれません。
またもうひとつダークシリコンの回避方法として、動作周波数が低い、弱いコアをたくさんのせるという手法もあります。これはメニーコア, MIC (Meny Integrated Core) なんて呼ばれています。これに関しては次に述べます。
高性能計算におけるCPUとGPU
メニーコアとは、簡単に言ってしまえばコア数を10や20というオーダーから数百、数千というレベルにまでふやしたマルチコア・プロセッサのことです。IntelはこれをMIC Architectureと呼んでいて、現在はXeon Phiというコプロセッサとして、60コア/240スレッドのプロセッサを利用することができます。(τ研にもXeon Phiのマシンあるよ!)現在のXeon PhiではPCI Expressに挿して使うような、いわゆる”アクセラレータ”に過ぎませんが、2015年末に出ると言われていた (まだ出てない) Knights Landingというバージョンでは、ホストプロセッサとして利用できるようになると言われています。このKnights LandingはAtomプロセッサのSilvermontをベースにしていると言われています。なので、2命令のOut-of-Order実行できるスーパースカラプロセッサになるのかな?このへんの性能がCore iシリーズやXeonなんかより低く、クロック周波数も低いので、1コアの性能は低いです。
さらに、この低い性能のコアでできるだけ高性能な計算をやるにあたって、SIMD演算というのが重要になってきます。(このリンク先のマイナビの記事は、コンピューターアーキテクチャの勉強をするためにググると必ず見ることになる、ような気がします。とてもよくまとまっていてすごいです。)SIMD演算は簡単に説明すると、ベクトルの演算みたいなものです。複数要素の足し算を1クロックでやる、とか、そういうことです。Xeon Phiでは512bitのレジスタがつかえるので、単精度の浮動小数点(float)だったら、32bit * 16要素を詰め込める、つまり16要素の演算が同時に行えるということになります。ただforループで足し算するだけならこのSIMD命令を利用するのは簡単かもしれませんが、ちょっと分岐が入ったり、ちょっと余計なことをするとすぐに使えなくなってしまいます。なので、これを簡単に扱えるようなことをする研究を後輩がやってたりします。
とここまでの話のなかで、よく知っている人であれば「え、これってGPUとなにが違うの???」と疑問をもつかもしれません。GPUはもともとグラフィックの処理に特化しているので、それぞれのピクセルに対して同じような計算をする、というシチュエーションに特化したアーキテクチャになっています。つまり、弱いコアを多数載せ、SIMD演算も大量につかって高速に処理をする、というアプローチを取っています。このGPUを汎用的につかうGPGPU (General Purpose GPU) もここしばらく流行っていて、たくさんの論文が出ています。
さて、ここまでの話のなかでGPGPUとMICの違いが不明瞭になってきました。実際、GPUはもともと別のメモリを持っていて、明示的にデータを転送しないと利用できなかったのですが、最近になってHSAやCUDA6のUnified Memoryなんていう仕組みがでてきています。これは、GPUとCPUのアドレス空間を統一的に扱えるとか、HSAではタスクのスケジューリングに関してもグラフィックと汎用演算とを自由にスケジュールできるように仕様がきまっていたりだとかするようです。ますますCPUとGPUの境界が近づいていると感じますね。
ただ、GPUはあくまでも一つの命令でたくさんのデータを動かすのが得意なプロセッサである、という決定的な違いがあります。CPUはもともと汎用演算のためにつくられているので、ifによる分岐の予測だとか、投機的実行だとか、そういうややこしいことをたくさんやって1つのスレッドを高速に動かそうという気持ちでつくられています。一方で、GPUはデカイデータに対して同じ演算をガーッとかけるために作られています。その根本が違うため、GPUではいろいろ分岐するようなプログラムは効率よく動作させることができません。また、GPU単体ですべてのプログラムを動作させるわけではないため、ホストのCPUで準備をし、GPUに仕事を投げ、もどってくるという複雑なプログラミングモデルを取らないといけなくなります。
個人的な意見としては、GPUは今盛り上がっていますが、今後はMICのほうが先が明るいのではないか、なんていうふうに思っています。このあたりの境界は曖昧ですが、すくなくとも、アクセラレータとしてのGPUはPCI Expressのようなバスを通した通信がボトルネックになってすぐに頭打ちになるのではないかな、と思います。GPUとCPUがもっと密にくっついて、速い幾つかのコアと小さい多数コア、どちらも命令セットは同じでスケジューラーがいい感じにやってくれる、なんていう世界が来たりするかな、なんて思ってたりします。と書きながら、これってARMのbig.LITTLEのLITTLEがたくさんバージョンなのでは・・・??と今書きながら思ってきました。
よりシンプルなアーキテクチャが最終的には生き残るのではないかな、と思っているので、シンプルにいい感じにMICが広がっていく、というものを個人的には想像しています。
メモリバンド幅の問題、TSVとHBM
コアが増えると、それだけメモリにアクセスする頻度が上がるということになります。これにより、1:コアあたりの利用可能なメモリ量が減る、2:コアあたりの利用可能なメモリバンド幅が減るという2つの問題が生じます。
まず1つめのメモリ量に関しては、DRAMのチップ当たりの容量が増加しにくくなっているという背景から、単純には解決できない問題となっているようです。そこで、現在はDRAMを3次元に積層するという方向で開発が進められており、それを実現するためにTSV (Through Silicon Via) という技術が注目されています[参考:【IRPS 2012レポート】 次世代シリコンの3次元実装技術「TSV」]。 TSVはシリコン上に穴を開けて、上下に複数枚のシリコンダイをくっつけちゃおうというお話になります。話としては単純ですが、シリコンの微細加工にあたって問題があったようで、最近ようやく実用化が進んできたところのようです。
また、TSVはただ上下がくっつくだけではなく、配線距離が短くなるという別の利点があります。これにより電気的な特性がよくなり、より高速な通信規格を利用できるようになります。ここにフォーカスした話がHBM (High Bandwidth Memory) になり、2つ目のバンド幅の問題を解決する方法の1つになります。
HBMに関してはこのへん[TSV技術で積層するGDDR5後継メモリ「HBM」の詳細]が詳しく説明してくれてるっぽいので、詳細についてはこっちに譲り、ここでは簡単な紹介をします。 HBMの基礎となるのは、2.5Dスタッキングという方法です。これは、インタポーザーと呼ばれるシリコンの基板の上に、CPUなどのプロセッサとDRAMを載せ、TSVをつかって配線する手法です。これにより、HBMは256GB/s程度まではいけるだろうと言われています。
また、もう一つのバンド幅に関する対応策として、eDDRと呼ばれるものがあります。これは、プロセッサの上に高速なDRAMを積んで、L4として使おうという試みです。これはHaswellから?の機能のようですが、Xeon PhiのKnights LandingもこのようなL4キャッシュに似た仕組みを導入するようです[参考:ISC 2015 - Intelが語った次世代Xeon Phi「Knights Landing」]。
このように、DRAMに関しては、積層技術の応用によって、容量やバンド幅はまだしばらくは増加していきそうな気配がします。
ストレージ:SSDのスワップとしての利用、NVDIMMと次世代不揮発性メモリ
今回のブログ最後のネタはストレージです。身近な話としては、一般に売られているノートPCにもSSDが載るようになって、HDDに比較し高い性能であることは体感しているかと思います。直近の話として、このSSDをフルに扱おうという動きがあります。OpenNVMではいくつかのインターフェースを提案していますが、特に個人的に面白いなと思ったのは、スワップ領域にSSDを利用しようというものです。現在はDRAMが一杯一杯になってしまった場合にしかたなくHDDにスワップをすることでなんとか動作を維持しよう、というような役割ですが、積極的にスワップを利用することで、大量のDRAMが存在するかのようなシステムを構成することができます。これは、SSDはHDDに比較するとランダムアクセス性能は高いという特徴を活かした面白い試みかと思います。
さらに、現在のストレージ向けの通信にはmSATAやPCI Expressといった規格が利用されていますが、これらは十分にランダムアクセス性能の高さを利用することができないため、DIMM(メモリがささっているところ)に刺すという機能が最近実装されつつあるようです[参考:NANDフラッシュをDIMMに載せたら ]。Linux kernel 4.2では、libnvdimmというもののサポートが行われたようです[参考:Linux 4.2 Will Bring LIBNVDIMM Support For Non-Volatile Memory Devices]。
しかし、SSDでもなおDRAMに比較すると十分とは言えません。まず、読み書き性能はHDDに比較すると十分スループットが出るとはいえ、そのレイテンシは依然としてmsオーダーだったりします[参考:M550 mSATA NAND Flash SSD]。この理由にも関係しますが、SSDに利用されている素子であるNAND Flashはページ単位でしか書き込みができない上に、書き換え回数に制限があります。そこで現在注目を浴びているのが、次世代不揮発性メモリです。
次世代不揮発性メモリはPersistent Memory, Storage Class Memoryなどとも呼ばれ、おおよそDRAMと同等の性能を持つとされる素子の総称です。代表的な手法に、PCM (Phase Change Memory)[参考], ReRAM (Resistive RAM)[参考], STT-RAM (Spin Torque Transfer RAM)[参考1, 参考2], Memristor[参考1, 参考2]といったものがあります。特にMemristorなんかは、1971年に"The missing circuit element"なんていう論文が出され、2008年に"The missing memristor found"という論文がでているという流れが非常にカッコいいですね。抵抗・コンデンサ(キャパシタ)・コイル(インダクタ)に続く第4の受動素子だそうです。
これらの次世代不揮発性メモリはそれぞれ多少特性が異なるものの、概ね(1)DRAMに匹敵する読み書き性能(とくにload/storeの発行からのレイテンシが低い), (2) NAND Flashに比較し書き換え回数の飛躍的増大 (3) バイト単位での永続化 というような特徴を持ちます。このようなデバイスの実現によりプログラミングモデルが変わると考えられていて、現在研究が盛んになっています。この辺りを去年の冬の輪講でまとめたので、そのときのスライドも見ていただけるといろいろな話があるんだ、とわかっていただけるかもしれません。
すでに次世代不揮発性メモリの商用化にむけた動きは始まっていて、Intelが3D XPointというのを発表しています[参考:3D XPoint™ Unveiled—The Next Breakthrough in Memory Technology]。特にこの記事なんかはとてもわかり易く3D XPointについてまとめてくださっていると思います。1000倍速い!1000倍書き換え回数が多い!なんて言われていますが、これは次世代不揮発性メモリの特徴そのものです。
個人的にはこの分野はちょうどいま面白いところに来ていると思っています。従来の"ブロック単位"での書き換えが前提だった世界からいかにして"バイト単位"の世界にシステムの設計を持ってくるのか。このへん、ページキャッシュの仕組みやmmapしたときのページフォルトの仕組みなど、ファイルシステム周りの変化がとても大きいんじゃないかなぁ、と感じています。DIMMにささってDRAMと同じアドレス空間をもつとなると、デバイスドライバの入る必要性がなくなるため、OSのファイルシステムは大きく変化せざるを得ないでしょう。 また、これに関連して、十分性能を活かそうと思うと仮想化まわりにもいろいろ考える余地がありそうですね。
まとめ
CPU、メモリ、ストレージに関して、僕の考えていることを交えながらざざっとまとめてみました。 ホントは非ノイマン型のCPUとか全部FPGAの世界とかも話書きたかったけど、ちょっと疲れちゃったので断念。 とりあえず、HPC (High Performance Computing) 向けにしろ、モバイル向けにしろ、ここから更に大きく発展していきそうだという僕の感じているワクワク感を共有できたら嬉しいなと思います。もし興味ある人がいたらぜひ語りましょう!
あと、こういう比較的低レイヤな話に興味を持ってくれるB3は、ぜひウチ研に来てくれるといいかなとおもいます!笑
書いてるうちにいろいろ触れたい話が増えていって、おもってたより長文になっちゃいました・・・ ここまで読んでくれた方、お疲れ様でした、ありがとうございます!!
Appendix
ただの行列行列積を何も考えずに1コアで実行すると、こんな感じです。ちなみに、ソースコードはここ
> ./mm.bin == Matrix Multiplication Test == Matrix size: 1024 Elapsed [ms]: 8207.92 Flops [GFLOPS]: 0.26
これを実行した環境はVAIO Pro 13です。使ってるCPUはi7-4500U CPU @ 1.80GHz, turbo boostで3.0GHzなので、1コアで本来なら3.0GHz * 2(FMA) * 4(要素) = 24GFLOPSくらいは出ることが期待できます。(SIMD命令はクロックが落ちるような気がしたけど、探してもみつからない・・・) ということで、ただの3重ループのなんの変哲もない行列積だと理論値性能の1%程度の性能しか出ないことがわかりました。
ちなみに、行列積のスパコンやXeonPhiノードを利用した高速化コンペティション、という課題がτ研の新B4向けの勉強会で開かれたりします。たのしみにしてください!
SECCON2015 Writeup - EEIC Advent Calendar Day 6
この記事はeeic Advent Calendar 2015の6日目の記事になります。
目次
はじめに
去年初めてやったSECCONではまとまった時間が取れずに悔しい思いをしたので、今年こそはもう少し・・・!と思い、参戦してみました。 今回は、EEICのメンバー(@Tak_Yaz, @meryngii, @wakanapo_eeic, @show_me_tech)を適当に集めて、SECCON2015のオンライン予選に参加しました。
チームの結果としては、以下の問題を解いて1900点、1251チーム中80位という順位でした。

皆CTF初心者の集まりとしてはわりと頑張ったのではないでしょうか。 チームで解いたものは以下です。
- [ 50] Start SECCON CTF
- [100] SECCON WARS 2015
- [100] Unzip the file
- [100] Reverse-Engineering Android APK 1
- [400] Reverse-Engineering Hardware 1
- [100] Connect the server
- [300] Exec dmesg
- [300] Decrypt it
- [200] QR puzzle (Windows)
- [100] Steganography 1
- [100] Steganography 3
- [ 50] Last Challenge (Thank you for playing)
チームメンバのwriteupはこちら。
- Tak_Yaz: SECCONに参加しました。(Write Upその他)
ここでは、僕の解いた/解こうとしたものについて簡単にメモを残していこうかと思います。
やったこと
Try 1: Unzip the file
とりあえず暗号化されたファイルが置いてあったので、ブルートフォースで解読するコマンド、fcrackzipを回しました。 ただ、しばらく経っても終わらなかったので、同時にこの問題触れていた@meryngiiにバトンタッチ。@meryngiiがbacknumber08.txt, backnumber09.txtを見つけていたので、それを使って解錠してくれたようです。
Try 2: Fragment2
Unzipしながら僕はこの問題に移行しました。問題としてはpcapファイルがあるだけなので、パケットをwiresharkとかで見たら100点問題だしすぐわかんだろー、とか思って気楽に開いたら、なんと1パケットだけ。 ペイロードはバイナリだけど、"Flag is in header"とかいうメッセージと、ポート80からのレスポンスだからおそらくHTTP界隈なのだろうということは理解しました。HTTPかつバイナリのペイロード、と言ったらHTTP2かな、とか思ったのだけどよく知らないので、とりあえずIP/TCPのヘッダをじっと見てみる。(大会終わってからTwitter見た感じ、これがよくなかったっぽい。)
なにもわからない。ということで、時間使ってるうちに次の問題が開かれたのでそっちに移行。
Try 3: Connect the server
Reverse-Engineering Hardware 1という問題を開いたら、大量のRaspberry Piとそれにつながったブレッドボードの写真、あとgpioをつかってflagを表示するpythonスクリプトが...
解けるけどめんどくさそう、となったのでまず簡単そうなこちらから解いてみました。
Connect the serverはFQDNとポート番号が与えられていたので、とりあえずncで接続。するとこんなのが出てきた。
The server is connected via slow dial-up connection. Please be patient, and do not brute-force. login:
何入れていいのかよくわからないけど、カチャカチャいじる。 で、しばらく悩んでたら
The server is connected via slow dial-up connection. Please be patient, and do not brute-force. login: Login timer timed out. Thank you for your cooperation. HINT: It is already in your hands. Good bye.
となったので、あぁ、なるほどということでwiresharkでパケットキャプチャしたらなんかフラグが出てきました。
100点げっと。
Try 4: Start SECCON CTF
まだこれ誰もトライしていなかったので、とりあえず解いてみる。 暗号と復号化後の値が2つサンプルで書いてあるのが問題。
ex1
Cipher:PXFR}QIVTMSZCNDKUWAGJB{LHYEO
Plain: ABCDEFGHIJKLMNOPQRSTUVWXYZ{}
ex2
Cipher:EV}ZZD{DWZRA}FFDNFGQO
Plain: {HELLOWORLDSECCONCTF}
quiz
Cipher:A}FFDNEVPFSGV}KZPN}GO
Plain: ?????????????????????
There is no bonus in this question
普通のシーザー暗号かなっておもったけど、カッコあるし違うじゃん。となり、PlainがABC順なのでマッピングテーブルをrubyでちゃちゃっとつくって解答。 50点。
Try 5: Reverse-Engineering Hardware 1
さて、400点問題、しかしただただ面倒なだけっぽい問題来ました。 こんな感じ。


大量の画像(ピンぼけ、影多数)からよーーーく見ると使われているICは74HC74ということでD-FFなのがわかります。で、プログラム中もDA, DBといっているのでまぁきっと読み間違いじゃないのだろうと確認。ただ、X1, X2, ..., X6とプログラム中にはあるけど、これは写真中のLEDの左からただ対応しているだけではないのだろうと推測し、きちんと線を追ってリバースエンジニアリングすることにしました。
つらい、、、、、つらい、、、、、、、、と無限に言いながら@wakanapo_eeicと頑張って書いた回路はこんな感じ。(これは最終版の正しいもの)
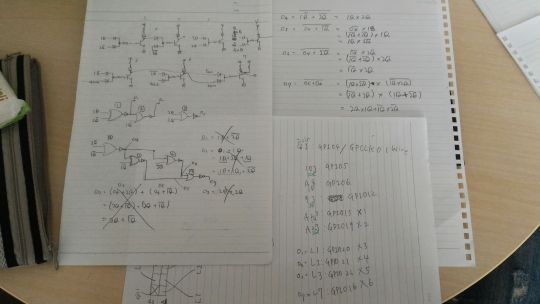
これの論理式を、もともとのgpio.pyへ突っ込んで、テスト。 間違い。
写真を見直すと、一箇所ピンを見間違えてた・・・。
修正。
間違い。
[1日目終了。とりあえず家帰って寝て翌朝。]
写真を見直すと、一箇所ピンを見間違えてた・・・。
修正。
間違い。
写真を見直すと、一箇所ピンを見間違えてた・・・。
修正。
これでフラグが出てきました。
SECCON{###FD80UY#!8880UY#!8}
これ、また間違いだったかと思ったよ・・・・・・・・・・・・・・
しかし、まったくもって筋肉な問題だったし、どういう意図だったのだろうか。。。
改変したgpio.pyはこんな感じです。
X1 = 0
X2 = 0
X3 = 0
X4 = 0
X5 = 0
X6 = 0
D1 = 0
D2 = 0
Q1 = D1
Q2 = D2
def x1(d1, d2, q1, q2):
return 1 if q1 else 0
def x2(d1, d2, q1, q2):
return 1 if q2 else 0
def x3(d1, d2, q1, q2):
return 1 if ((not d1) and q2) else 0
def x4(d1, d2, q1, q2):
return 1 if ((d1 and q1) or (not q2 and q1)) else 0
def x5(d1, d2, q1, q2):
return 1 if (not (d2 or q2)) else 0
def x6(d1, d2, q1, q2):
return 1 if (q1 and q2) or (not q1 and not q2) else 0
def encoder(x6,x5,x4,x3,x2,x1):
v = 0
v = x1;
v = 2*v + x2
v = 2*v + x3
v = 2*v + x4
v = 2*v + x5
v = 2*v + x6
return v
c = '@'
flag = ""
def calculate():
global X1, X2, X3, X4, X5, X6, D1, D2, Q1, Q2
X1 = x1(D1, D2, Q1, Q2)
X2 = x2(D1, D2, Q1, Q2)
X3 = x3(D1, D2, Q1, Q2)
X4 = x4(D1, D2, Q1, Q2)
X5 = x5(D1, D2, Q1, Q2)
X6 = x6(D1, D2, Q1, Q2)
print(Q1, Q2, X3, X4, X5, X6)
# print(D1, Q1, D2, Q2, X1, X2, X3, X4, X5, X6)
def clock():
global D1, D2, Q1, Q2
Q1 = D1
Q2 = D2
for i in range(10) :
if c == 'Y' : # 0x39 = 0x111001
D1 = 0
D2 = 1
# GPIO.output(DA, False)
# GPIO.output(DB, True)
else:
if (i & 1) == 0 : # 偶数
D1 = 0
else :
D1 = 1
if (i & 2) == 0 : # x % 4 <= 1
D2 = 0
else :
D2 = 1
calculate()
# time.sleep(0.1)
c = chr(encoder(X6,X5,X4,X3,X2,X1)+32)
flag = flag + c
# GPIO.output(CLK, True)
# GPIO.output(CLK, False)
clock()
calculate()
# time.sleep(0.1)
flag = flag + chr(encoder(X6,X5,X4,X3,X2,X1)+32)
print "The flag is SECCON{"+flag+"}"
Try 6: Individual Elebin
これは、ひたすらいろんなbinを実行するという問題。 fileコマンドしたらこんな感じ。
$ ls 1.bin* 10.bin* 11.bin* 2.bin* 3.bin* 4.bin* 5.bin* 6.bin* 7.bin* 8.bin* 9.bin* $ for i in `seq 1 11`; do file $i.bin; done 1.bin: ELF 32-bit LSB executable, Intel 80386, version 1 (FreeBSD), statically linked, stripped 2.bin: ELF 32-bit MSB executable, MC68HC11, version 1 (SYSV), statically linked, stripped 3.bin: ELF 32-bit LSB executable, NEC v850, version 1 (SYSV), statically linked, stripped 4.bin: ELF 32-bit MSB executable, Renesas M32R, version 1 (SYSV), statically linked, stripped 5.bin: ELF 64-bit MSB executable, Renesas SH, version 1 (SYSV), statically linked, stripped 6.bin: ELF 32-bit MSB executable, SPARC, version 1 (SYSV), statically linked, stripped 7.bin: ELF 32-bit LSB executable, Motorola RCE, version 1 (SYSV), statically linked, stripped 8.bin: ELF 32-bit LSB executable, Axis cris, version 1 (SYSV), statically linked, stripped 9.bin: ELF 32-bit LSB executable, Atmel AVR 8-bit, version 1 (SYSV), statically linked, stripped 10.bin: ELF 32-bit LSB executable, ARM, version 1, statically linked, stripped 11.bin: ELF 32-bit MSB executable, MIPS, MIPS-I version 1 (SYSV), statically linked, stripped
とりあえず1は普通に実行できたけど、2.binからは環境がない。しかし、
$ strings 2.bin B76_76 890123456789abcdef GCC: (GNU) 3.4.6 .shstrtab .text .rodata .data .bss .stack .comment
ということで、2.binはきっとB76_76なのだろうと推測がつく。でも、3.binからは
$ strings 3.bin 0123456789abcdef GCC: (GNU) 3.4.6 .shstrtab .text .rodata .data .bss .stack .comment
9.binにいたっては、
$ strings 9.bin l/}/d h/y/ /_?OA !P0@A h/y/ F/W/ O__OO?Q (/3' O__OO?Q H/Y/O__OPp h/w' h.y. .F/W/n/ 1/ /_-N-}-l- L/]/O]_O ,/=//_?Oq/`/ 0123456789abcdef .shstrtab .text .trampolines .data .bss .stack
あぁ、さすがに実行しないと許してくれないのね、と悲しい気持ちになりました。
んじゃぁ、qemuで実行してやろうじゃないの、ということで実行。
$ qemu-mips 11.bin qemu: uncaught target signal 11 (Segmentation fault) - core dumped zsh: segmentation fault (core dumped) qemu-mips 11.bin
実行できない・・・・
ぶっちゃけqemuたたくの初めてだしなーよくわかんねぇなー、ということで諦めて次の問題へ移行しました。
Try 7: Reverse-Engineering Hardware 2
これもマッチョ系か・・・ということでみてみると、今度は配線が綺麗。

利用しているICは74HC161と記述があったので、バイナリカウンタがただ並んでいるだけのように見えます。
回路を(@wakanapo_eeicが)カンバって起こしてみると、どうやらバイナリカウンタをサイクリックシフトしたものがプログラムの入力の1byteになっているようだということまで確認し、付属していたpythonのコードを改変したのが以下。
#!/usr/bin/env python # import RPi.GPIO as gpio import time import sys import struct rfd = open(sys.argv[1], 'rb') wfd = open(sys.argv[2], 'wb') len = int(sys.argv[3]) load = 4 clock = 10 reset = 9 p0=21 p1=20 p2=16 p3=12 p4=25 p5=24 p6=23 p7=18 pns = [p7,p6,p5,p4,p3,p2,p1,p0] q0=19 q1=13 q2=6 q3=5 q4=22 q5=27 q6=17 q7=26 class Counter(): def __init__(self): self.n = 0 def init(self): self.n = 0 def setValue(self, n): self.n = n def getPin(self, x): if (x == q0): return 1 if self.n & (1 << 1) else 0 if (x == q1): return 1 if self.n & (1 << 2) else 0 if (x == q2): return 1 if self.n & (1 << 3) else 0 if (x == q3): return 1 if self.n & (1 << 4) else 0 if (x == q4): return 1 if self.n & (1 << 5) else 0 if (x == q5): return 1 if self.n & (1 << 6) else 0 if (x == q6): return 1 if self.n & (1 << 7) else 0 if (x == q7): return 1 if self.n & (1 << 0) else 0 return -1 def clock(self): self.n += 1 def pulse(pin): pass # gpio.output(pin, gpio.LOW) # gpio.output(pin, gpio.HIGH) def init(): pass # gpio.setwarnings(False) # gpio.setmode(gpio.BCM) # gpio.setup([clock,load,reset], gpio.OUT) # gpio.output([clock,load,reset], gpio.HIGH) # pulse(reset) # gpio.setup(pns, gpio.OUT) # gpio.output(pns, gpio.LOW) # for q in [q7, q6, q5, q4, q3, q2, q1, q0]: # gpio.setup(q, gpio.IN) def setValue(n): pulse(reset) for i in range(n): pulse(clock) def a2v(a): return a[7]+2*a[6]+4*a[5]+8*a[4]+16*a[3]+32*a[2]+64*a[1]+128*a[0] # main init() counter = Counter() for i in range(len): # value = a2v([gpio.input(q7), gpio.input(q6), gpio.input(q5), # gpio.input(q4), gpio.input(q3), gpio.input(q2), # gpio.input(q1), gpio.input(q0)]) value = a2v([counter.getPin(q7), counter.getPin(q6), counter.getPin(q5), counter.getPin(q4), counter.getPin(q3), counter.getPin(q2), counter.getPin(q1), counter.getPin(q0)]) # file convert v = rfd.read(1) d = '' d += struct.pack('B', ord(v) ^ value) wfd.write(d) # setValue(value) counter.setValue(value) # time.sleep(0.1) # value+3 counter.clock() counter.clock() counter.clock() # pulse(clock) # pulse(clock) # pulse(clock) # gpio.cleanup()
で、入力に付属のencryptedを食わせて出力をみてみたら、どうやらgzipらしいということがわかった。
が、しかし。ここからが解けない。gzipコマンドをつかって修復を試してみも解凍できないし、この67バイトのバイナリは一体なんなのか・・・? というのがわからずに諦めて次の問題へ。
Try 8: Micro computer exploit code challenge
問題は以下。
サーバーURL 10000
* プログラムはサーバの10000番ポートで稼働中
* フラッグ "SECCON{...}" はマシンコードの 0x1800 にある
* プログラムはGDBシミュレータの上で動いている
(gdb-7.10 + special patch for read service)
avr-elf.x
もともとAVRは使っていたので環境が整っている気がするぞラッキー、と思いながら、すでに始めていた@meryngiiを手伝い始めました。 avr-elf.xはAVRマイコン向けのバイナリだということがfileコマンドからもわかったので、avr-objdumpでアセンブラからスタート。
これは、そのうちのメインルーチン(唯一入力を受け取る部分)のproc関数です。
00001126 <proc>:
1126: cf 93 push r28
1128: df 93 push r29
112a: cd b7 in r28, 0x3d ; 61
112c: de b7 in r29, 0x3e ; 62
112e: 60 97 sbiw r28, 0x10 ; 16
1130: 0f b6 in r0, 0x3f ; 63
1132: f8 94 cli
1134: de bf out 0x3e, r29 ; 62
1136: 0f be out 0x3f, r0 ; 63
1138: cd bf out 0x3d, r28 ; 61
113a: 83 e2 ldi r24, 0x23 ; 35
113c: 98 e1 ldi r25, 0x18 ; 24
113e: 0e 94 70 08 call 0x10e0 ; 0x10e0 <puts>
1142: ce 01 movw r24, r28
1144: 01 96 adiw r24, 0x01 ; 1
1146: 0e 94 60 08 call 0x10c0 ; 0x10c0 <gets>
114a: 80 e3 ldi r24, 0x30 ; 48
114c: 98 e1 ldi r25, 0x18 ; 24
114e: 0e 94 70 08 call 0x10e0 ; 0x10e0 <puts>
1152: ce 01 movw r24, r28
1154: 01 96 adiw r24, 0x01 ; 1
1156: 0e 94 70 08 call 0x10e0 ; 0x10e0 <puts>
115a: 8c e1 ldi r24, 0x1C ; 28
115c: 98 e1 ldi r25, 0x18 ; 24
115e: 0e 94 70 08 call 0x10e0 ; 0x10e0 <puts>
1162: 80 e0 ldi r24, 0x00 ; 0
1164: 90 e0 ldi r25, 0x00 ; 0
1166: 60 96 adiw r28, 0x10 ; 16
1168: 0f b6 in r0, 0x3f ; 63
116a: f8 94 cli
116c: de bf out 0x3e, r29 ; 62
116e: 0f be out 0x3f, r0 ; 63
1170: cd bf out 0x3d, r28 ; 61
1172: df 91 pop r29
1174: cf 91 pop r28
1176: 08 95 ret
AVRの関数呼び出しのconvention ruleをググって、r24, r25が関数の引数/返り値だということを把握しました。また、in r28, 0x3d/in r29, 0x3eはスタックポインタだということもAVRの命令セット一覧からわかりました。
で、この関数はr28, r29をpushしたあと、スタックを0x10下げているので、getsのバッファ(0x10バイト、つまり16バイト)をこえると、17バイト目がr29, 18がr28となり、19/20バイト目がprocからの戻り番地になっていると考えられます。
しかし。そうなるように入力を与えてもプログラムカウンタを好きなところに飛ばせない。飛ばしたあとの処理も思いついていない上にこれではどうしようもないなぁ。というところで残り30分。
残り30分はいろいろパパっと他の問題見たり、@muscle_azosonが4042を解けそうになっていたのでそれを手伝ったりしましたが、得点にはつながらなかったです。
END
僕が絡んだ得点は結局550点でした。
おわりに
QRコードが死ぬほど出てたり、ハードウェアのマッチョ系問題があったりと初心者でも労力かければ解ける系問題が案外多いなぁと思いましたし、そこからある程度得点を稼ぐことができたように感じます。(こんなもんなのかな?)
一方、バイナリだとかネットワークだとかはなかなか知識が足りずに難しく、スッキリ解くことができなくて辛かったです。
またもうちょっと知識を付けてぜひ再戦したいですね。興味ある人いたらぜひ声かけて下さいな。”コンピューター”のいろんな知識がつくのでとてもおすすめです。
mDNSの謎について
動機
もともと, macでbonjourっていうやつによって*.localという名前で名前解決ができるようになっているという知識と、同様のことがlinuxではavahi-daemonというものをインストールすることによってできるということは知っていた。しかし、その仕組みについては全然勉強していなかったので学んでみた。
mDNSの詳細について
もともとは2000年に提案された仕組みっぽい。割と新しいなとおもったけどもう15年も前の話なのか。 で、このmDNSというのはzeroconf, ゼロコンフィギュレーションネットワークという枠組み(?)のなかの一つのお話っぽくて、zeroconfはとても便利っぽい話っぽい。あまり広がっていないような気がしたけど、僕はUPnPとか使ったりしてるし意外と徐々に広まりつつあるのかもしれない。と考えたところでUPnPの仕組みもしらないことに気づいたのでそのうち勉強したい。
で、肝心のmDNSの話だが、Bonjourのドキュメントのp12に簡単に書いてあった。
Because these DNS queries are sent toa multicast address, no single DNS server with global knowledge is required to answer the queries.
つまり、mDNSを使えるノードはマルチキャストアドレス(224.0.0.251)のUDP, ポート5353にDNSのクエリをなげ、対応するマシンがいればそのノードが返事を返すというような感じっぽい。意外と単純だった。
いろいろ調べてるついでに、mDNS - A Proposal for Hierarchical Multicast Session Directory Architecture(ICOMP'08)なんていう論文もみつかった。abstractしか読んでないけど、これは名前解決に関してまとめた論文なのかな?
global deployment which may allow end users to enjoy the true power and eciency of IP multicast.
なんて言っているけど、IP multicastってそんなに新しい技術なのだろうか?(よく知らない)
nsswitch
名前解決の順序を決め、順番に名前解決を行うシステム。設定ファイルは/etc/nsswitch.conf。
僕の/etc/nsswitch.confは以下のようになっている。 hostsが, files, mdns4_minimul dnsとなっているので、/etc/hosts探してからmdnsを行い、なければdnsを行うという手順であることがわかる。
_minimulの意味だが、mDNSで.localのホストの名前解決を行う(nss-mdns*)に詳しい説明が記述されている。簡単にまとめると、*.localというホスト名であればmdnsするし、そうでなければ即時にスキップするということらしい。これによって無駄にmdnsをすることをなくしているようだ。
# /etc/nsswitch.conf # # Example configuration of GNU Name Service Switch functionality. # If you have the `glibc-doc-reference' and `info' packages installed, try: # `info libc "Name Service Switch"' for information about this file. passwd: compat group: compat shadow: compat hosts: files mdns4_minimal [NOTFOUND=return] dns networks: files protocols: db files services: db files ethers: db files rpc: db files netgroup: nis
Bluetoothのはなし(4)|Wireless・のおと|サイレックス・テクノロジー株式会社
Link: Bluetoothのはなし(4)|Wireless・のおと|サイレックス・テクノロジー株式会社
EdisonでBluetoothのslaveをやらせようと思ったときに、bluezに関してなにも理解していなことに気づいたので、リンク先のページを見てお勉強。
とりあえず、bluezは各種のツール群(hcitoolなど)と、SDPなどを司るデーモンと、実際の物理層を叩くカーネルモジュールのセットだということは理解した。しかし、依然としてagentはいまいちよくわからない。agentというのはbluezのAPI(D-BUS?)をたたく主体、いわばアプリケーションのことなのだろうか????
Intel EdisonでBluetoothを試してみる によると、bluetoothctlでDisplayYesNoだのDisplayOnlyだの選ぶっぽいので、これをNoInputNoOutputにすればEdisonでうまくslaveになれるのではないかと思ったのだけど、これはbluezを使うAgentに関する設定ということなのかな?
How to set up remote desktop sharing through SSH?
Link: How to set up remote desktop sharing through SSH?
ubuntuのサーバーのリモートデスクトップをsshしかできない状況から有効化する方法。
WM×LI: LaTeXでHelveticaフォントを埋め込む
Link: WM×LI: LaTeXでHelveticaフォントを埋め込む
Helveticaだけフォントが埋め込まれてなかったので、standardfontsとかいうのを消してやればいいという話。こうやって解説してあるところがたくさんあるけど、本当にコレでいいのかは疑問。(バージョンアップしたときに死んじゃうし。)
これもフォントマップのファイルを適当にいじることでなんとかならないかなあ。